深度学习工作站攒机指南
引言
接触深度学习已经快两年了,之前一直使用Google Colab和Kaggle Kernel提供的免费GPU(Tesla K80)训练模型(最近Google将Colab的GPU升级为Tesla T4,计算速度又提升了一个档次),不过由于内地网络的原因,Google和Kaggle连接十分不稳定,经常断线重连,一直是很令人头痛的问题,而且二者均有很多限制,例如Google Colab一个脚本运行的最长时间为12h,Kaggle的为6h,数据集上传也存在问题,需要使用一些Trick才能达成目的,模型的保存、下载等都会耗费很多精力,总之体验不是很好,不过免费的羊毛让大家撸,肯定会有一些限制,也是可以理解的。
对于租用云服务器,之前也尝试过,租用了一家小平台的GPU服务器,也存在一些操作上的困难,不适合程序调试,而且价格也不便宜。
很早之前就想要搭建一个自己的深度学习工作站,不过机器成本的昂贵,一直阻碍着我攒机计划的进行。工欲善其事,必先利其器!最近终于下定决心,置办一个深度学习工作站主机。本文将我在这段时间选择、购置硬件的心得体会,分享给大家。
配置清单
| 配件 | 品牌型号 | 数量 | 价格 | 渠道 |
|---|---|---|---|---|
| CPU | Intel 酷睿i7 6950X 至尊版 | 1 | 3300 | 散片 |
| 主板 | 华硕 RAMPAGE V EXTREME X99 主板 | 1 | 1085 | 二手 |
| 内存 | 海盗船 复仇者LPX 16GB DDR4 2400 | 4 | 1920 | 全新 |
| HDD | 西部数据 WD40EZRZ 蓝盘 4TB | 1 | 550 | OEM |
| SSD | 西数 WDS100T2X0C 黑盘 1TB | 1 | 1220 | 全新 |
| 显卡 | 影驰 GeForce RTX 2070 大将 | 1 | 3400 | 全新 |
| 机箱 | 爱国者(aigo)月光宝盒 破晓 | 1 | 264 | 全新 |
| 电源 | 鑫谷 GP1350G 1250W | 1 | 680 | 全新 |
| 散热器 | 爱国者(aigo)冰塔T240 极光版 | 1 | 299 | 全新 |
| 风扇 | 金河田 光影炫光 12CM | 6 | 60 | 全新 |
| 12778 | 总计 |
以上就是我主机的配置清单,目前只买了一张2070,后期会升级加入多卡,下面将详细分析一下各个配件的选购过程。
配件选购指南
主板
有很多朋友在进行选购主机的时候认为应该先选CPU再选主板,个人认为配件选购的顺序和主机的用途是有关系的,对于搭建深度学习工作站而言,在正式进行硬件选购前,最重要的是需要确认一个问题,到底需要单卡(GPU)主机还是多卡主机,如果只需要搭建单显卡的主机,那么在选购主板的过程中,不需要花费太多精力,大量主板可以满足要求,如果想要搭建双卡、三卡或是四卡主机,则需要在主板上下点功夫,为了日后升级方便,我的目标是使用可支持四显卡的主机,所以在主板选择方面,会很注重PCIE扩展接口数量。
在初期选择主板时,网上各式各样型号的主板会使小萌新(我)很是懵逼,在网上查找了些资料,了解了些主板的知识。为了保证CPU和主板搭配合理,装到一起能正常工作,首先我们需要了解各主板芯片组和CPU接口的具体含义。例如,下图为京东的主板截图。
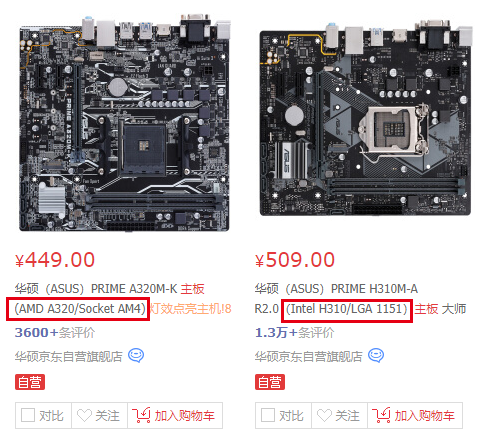
我们可以看到大多数商品名称后面都会有一个类似(AMD A320/Socket AM4)或(Intel H310/LGA 1151)的注释,其实这些就是影响你CPU和主板能否匹配的最重要参数了,在商品详情页,我们也可以找到这个参数,前面的“Intel H310”或“AMD A320”指的就是主板的芯片组,而后面的“LGA 1151”或“Socket AM4”指的就是主板上CPU插槽的类型了。
芯片组
芯片组示主板的核心芯片,选对芯片组,主板和CPU才能兼容。目前主流的主板分为Intel和AMD两个系列,分别对应不同品牌的处理器。而每个系列又按照芯片组类型的不同,分为很多子系列。以Intel系列主板为例,在市面上可以看到华硕、技嘉、七彩虹等近十个品牌的产品,不同品牌的主板在外观和技术上会有一些差别,但他们使用的芯片组都是由Intel提供的。

不过,虽然同属于Intel系列主板,但根据处理器的不同,需要搭配对应芯片组的主板才能成功组建出一台可以使用的主机。比如目前Intel最新的九代酷睿 i9-9900k 处理器需要搭配Z390、Z370或H370芯片组的主板来使用。而AMD的Ryzen 3/5/7系列CPU和APU产品则可以搭配X370、B350或A320芯片组的主板。
那么不同芯片组的主板又有什么区别呢?有的时候,多个芯片组的主板虽然可以支持同一款处理器,但在主板的规格上还是有一定区别的。这些区别包括但不限于原生USB及磁盘接口数量、是否支持CPU超频、是否支持多显卡互联等。这对于不太了解主板的用户来说确实很难选择,简单总结一下:
B系列(如B360、B250)属于入门级产品,不具备超频和多卡互联的功能,同时接口及插槽数量也相对要少一些。
H系列(如H310)比B系列略微高端一些,可以支持多卡互联,接口及插槽数量有所增长。
Z系列(如Z390、Z370)除了具备H系列的特点支持,还能够对CPU进行超频,并且接口和插槽数量也非常丰富。
X系列(如X99、X299)可支持Intel至尊系列高端处理器,同时具备Z系列的各项特点。
同时,Intel的100系列和200系列主板可以搭配6代及7代酷睿处理器,300系列主板需要搭配8代酷睿处理器,X299系列主板需要搭配7代至尊系列酷睿处理器。
对于单路CPU的主板,能够同时支持四张显卡卡的神板,毫无疑问就只有X99/X299系列的主板了,当然你也可以考虑intel 服务器C系列多路CPU主板,可以支持两个CPU在一张主板上。我的目标是使用单路CPU,所以也就没有关注C系列主板。
对于X299和X99之间的选择,有的朋友会主张买新不买旧,我个人的建议还是性价比高才是好的,较新的X299板子相比X99主板要贵大几百甚至1k左右,功能上的提升并不是很大,对于我们大多数Deep Learning开发者而言,X99的板子足够了,毕竟要把钱花在刀刃上,GPU才是大手笔。X99板子主要推荐以下三款:

Asus/华硕 RAMPAGE V EXTREME/U3.1

对比
| 型号名称 | MSI/微星 X99S GAMING 7 | 华硕RAMPAGE V EXTREME/U3.1 | 华硕X99-E WS/USB 3.1 |
|---|---|---|---|
| 主芯片组 | Intel X99 | Intel X99 | Intel X99 |
| CPU插槽 | LGA 2011-v3 | LGA 2011-v3 | LGA 2011-v3 |
| 内存规格 | 8×DDR4 DIMM 四通道 | 8×DDR4 DIMM 四通道 | 8×DDR4 DIMM 四通道 |
| 最大内存容量 | 128GB | 128GB | 128GB |
| PCI-E标准 | PCI-E 3.0 | PCI-E 3.0 | PCI-E 3.0 |
| PCI-E插槽 | 4×PCI-E X16 插槽 | 5×PCI-E X16 插槽 1×PCI-E X1 插槽 |
7×PCI-E X16 插槽 |
| 存储接口 | 10×SATA III 1×SATA Express 1×M.2(10Gb/s) |
1×M.2 2×SATA Express 8×SATA III |
1×M.2 2×SATA Express 8×SATA III 2×eSATA |
| USB接口 | 6×USB2.0(2背板+4内置) 12×USB3.0(4背板+8内置) |
14×USB3.0(4内置+10背板) 6×USB2.0(4内置+2背板) |
14×USB3.0(4内置+10背板) 4×USB2.0(4内置) |
| 主板板型 | ATX板型 | E-ATX板型 | E-ATX板型 |
| 外形尺寸 | 30.5×24.4cm | 30.5×27.2cm | 30.5×26.7cm |
| 多显卡技术 | NVIDIA 3-Way SLI NVIDIA 3-Way SLI |
NVIDIA 4-Way SLI AMD 4-Way CrossFireX |
NVIDIA 4-Way SLI AMD 4-Way CrossFire |
可以看到这三款主板,均为X99芯片组,CPU插槽均为 LGA 2011-v3 ,而且有8个内存插槽,支持四通道,最高128G的内存容量,内存容量这部分个人很喜欢,对于大型数据集数据预处理的过程,对内存容量和CPU要求都很高,而且足够的内存容量使你不用再为多开窗口卡顿现象而担忧。三者都支持多显卡扩展,华硕R5E和华硕X99 E-WS均支持4显卡交火,微星X99S Gaming 7支持3显卡交火,不过显卡交火,对于深度学习计算没有任何的帮助,对游戏确是有一些提升,我们日常所说的多显卡训练模型,也不是用到交火技术,而是Data Parallel或Model Parallel,所以交火与否我们不需要关注,需要关注的时PCIE ×16扩展插槽的有效个数(有的间距太近,无法全插)。
起初最想购买的是“华硕 X99-E WS”,经典的工作站主板,很多深度学习开发者的首选,支持四路显卡交火,更为优秀的是竟然有7个×16全速PCIE 3.0扩展插槽,但是对于这类主板虽然有如此强大的扩展功能,但在真正插显卡的时候,由于PCIE接口之间的空间限制,你是无法插满插槽的,而且现在显卡都很厚,很可能会造成接口的浪费。这个板子已经停产,不过在天猫的华硕旗舰店仍然有存货,售价“3899元”,还是很贵的。其中有很多功能,对于我们日常使用、训练模型来讲并不是很用得上,会造成没必要的开销。最后我选择了在淘宝购买二手的“华硕 RAMPAGE V EXTREME”,毕竟便宜。如果经费充足的朋友,我仍然建议购买“华硕 X99 E-WS”这个主板。
CPU
对于CPU的选取是基于确定主板CPU插槽类型为前提的,例如我们上文中我们选择的X99系列三款主板,CPU插槽类型均为“LGA 2011-v3”,我们就要选与此匹配的CPU,各插槽类型的CPU具体有哪些型号,可以去中关村在线查询,里面还有一些性能测评的文章和排行榜信息,值得推荐。
为了能够为CPU做出明智的选择,我们首先需要了解CPU以及它与深度学习的关系。CPU为深度学习做了什么?当你在GPU上运行深度网络时,CPU几乎不会进行任何计算。它主要的作用是:(1)启动GPU函数调用,(2)执行CPU函数。
CPU对于数据预处理的过程却起重要作用。有两种常见的数据处理策略,它们具有不同的CPU需求。
1 | # 一、在训练时进行数据预处理 |
对于第一个策略,为避免CPU的性能成为训练模型的速度的瓶颈,具有高主频多内核的CPU可以显著提高性能,加快训练速度。对于第二种策略,由于是预先进行数据预处理,在训练时的速度取决于GPU性能,与CPU无关,理论上CPU的性能不会成为瓶颈。但是我个人的观点还是,在经费允许的情况下,尽管CPU的性能越强大越好,但是也不一定非要追求最新款、最强大的CPU,性价比和个人需求才是最关键的。
当然,此处附加一点说明,如果攒机后不仅需要训练模型,而且偶尔也会玩一些游戏消遣的话,尽量选择高主频的主机,志强系列多核心低主频CPU不适合游戏玩家。
PCIe 通道
CPU的PCIe通道对模型训练的影响网上也纵说纷云,首先让我们先了解一下什么是CPU的PCIe通道
PCI-Express(peripheral component interconnect express)是一种高速串行计算机扩展总线标准,它原来的名称为“3GIO”,是由英特尔在2001年提出的,旨在替代旧的PCI,PCI-X和AGP总线标准。PCIe属于高速串行点对点双通道高带宽传输,所连接的设备分配独享通道带宽,不共享总线带宽,主要支持主动电源管理,错误报告,端对端的可靠性传输,热插拔以及服务质量(QOS)等功能。
简而言之,PCIe通道就是主机中各组件进行数据交互的信道,PCIe通道分两种:
- CPU直连通道,主流消费级只给你16条(8700K),高端&服务器上才会多给(7980XE)。
- DMI3总线PCH芯片分发出来的,是主板的属性。例如Z370主板声称有24条PCIE通道,其实这24条就是PCH通道,要共享DMI3等效直连PCIe ×4的带宽。
就PCH而言,在很多高性能扩展面前没有智联通道强大,所以对于CPU的直连通道数就显得至关重要了。
Tim Dettmers大神在他的博文《A Full Hardware Guide to Deep Learning》中也做出了对PCIe通路的见解,Tim认为在单机少量(小于4)GPU的主机中,PCIe通路对模型训练的影响并不是很大,但对于大于4个GPU或GPU集群PCIe通路的影响就会很显著。在文章中,Tim对比了不同通道数量在模型训练过程中的速度传输速度对比。
CPU and PCI-Express
People go crazy about PCIe lanes! However, the thing is that it has almost no effect on deep learning performance. If you have a single GPU, PCIe lanes are only needed to transfer data from your CPU RAM to your GPU RAM quickly. However, an ImageNet batch of 32 images (32x225x225x3) and 32-bit needs 1.1 milliseconds with 16 lanes, 2.3 milliseconds with 8 lanes, and 4.5 milliseconds with 4 lanes. These are theoretic numbers, and in practice you often see PCIe be twice as slow — but this is still lightning fast! PCIe lanes often have a latency in the nanosecond range and thus latency can be ignored.
Putting this together we have for an ImageNet mini-batch of 32 images and a ResNet-152 the following timing:
- Forward and backward pass: 216 milliseconds (ms)
- 16 PCIe lanes CPU->GPU transfer: About 2 ms (1.1 ms theoretical)
- 8 PCIe lanes CPU->GPU transfer: About 5 ms (2.3 ms)
- 4 PCIe lanes CPU->GPU transfer: About 9 ms (4.5 ms)
Thus going from 4 to 16 PCIe lanes will give you a performance increase of roughly 3.2%. However, if you use PyTorch’s data loader with pinned memory you gain exactly 0% performance. So do not waste your money on PCIe lanes if you are using a single GPU!
When you select CPU PCIe lanes and motherboard PCIe lanes make sure that you select a combination which supports the desired number of GPUs. If you buy a motherboard that supports 2 GPUs, and you want to have 2 GPUs eventually, make sure that you buy a CPU that supports 2 GPUs, but do not necessarily look at PCIe lanes.
PCIe Lanes and Multi-GPU Parallelism
Are PCIe lanes important if you train networks on multiple GPUs with data parallelism? I have published a paper on this at ICLR2016, and I can tell you if you have 96 GPUs then PCIe lanes are really important. However, if you have 4 or fewer GPUs this does not matter much. If you parallelize across 2-3 GPUs, I would not care at all about PCIe lanes. With 4 GPUs, I would make sure that I can get a support of 8 PCIe lanes per GPU (32 PCIe lanes in total). Since almost nobody runs a system with more than 4 GPUs as a rule of thumb: Do not spend extra money to get more PCIe lanes per GPU — it does not matter!
不过依我个人的看法,还是要选支持PCIe通道数大一点的CPU,毕竟M.2 NVME SSD就会占据四条通道,如果我们CPU只支持16通道,并且有两个GPU的话,每个GPU只能分到×4的速度,这个总感觉不太好。显卡已经花了那么多钱,我们当然希望它能全速跑,不要由于CPU PCIe通路的短板影响整体的性能,得不偿失。所以我更倾向于选择40条通路的CPU。目前主流CPU大多支持16通道、24通道,对于至尊系列CPU会有支持40通道的,对于大部分志强系列服务器CPU大多数支持44通道。
对比
对于志强系列,网上所有渠道都基本是拆机CPU,很多是外国服务器淘汰下的CPU,质量方面,由于没有使用过,不妄加评论。志强系列U特点是核心多,单核主频低,如果对于高并发有需求的朋友,可以优先选择志强系列U,搭配双路服务器主板。但对于我个人来讲,对单核主频要求高一些,所以我更倾向于桌面级CPU。
在我选择CPU的过程中,CPU天梯图对我很有帮助,很直观的展现了Intel/AMD所有CPU的性能排行,也推荐给大家。
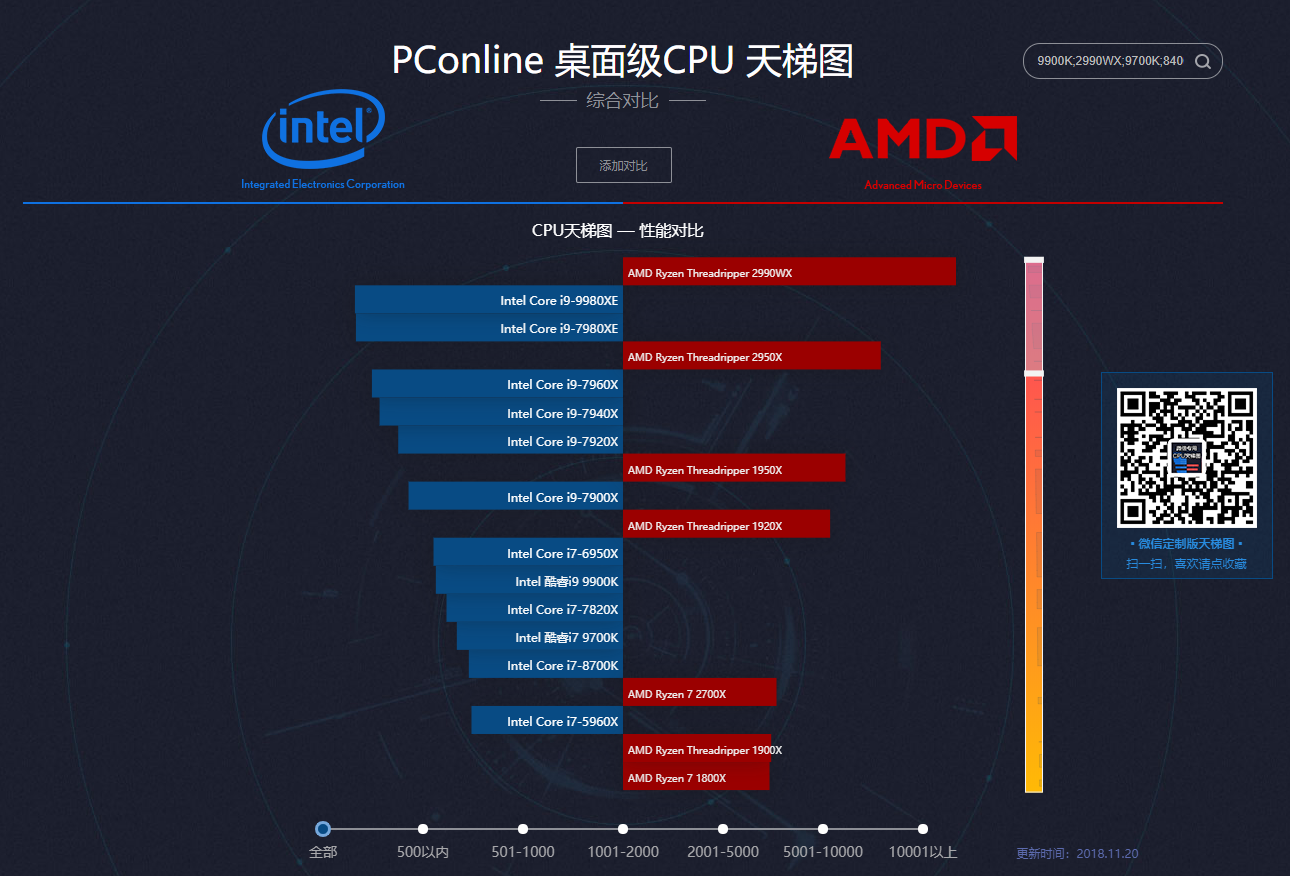
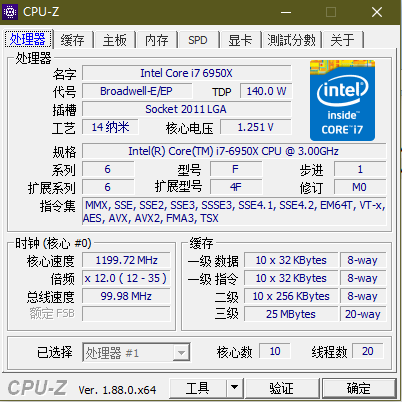
经过反复的对比,最终锁定了两款CPU“i7-6850K”和“i7-6950X”,首先首先我先解释一下为什么没有选择最新的九代酷睿系列,目前九代酷睿发布没多久,例如“I9-9900K”也是炒的很火热, 虽然最新系列的CPU单核主频都有所提高,但是核心数并没有太大改善,致使CPU整体性能(多核性能)并不是越新越好,从上方的天梯图我们也可以看出,“I7-6950X”排在”I9-9900K”前面,第二个原因就是,CPU是一个没什么损耗的器件,如果没有变态超频使用的话,全新和二手的U新能没什么区别,对于这些已经停产的CPU,网上流通的都是拆机的二手版本,只要选择正式版(不要QS/ES版本),其实都可以的,而且价格便宜,性价比极高,例如我们Intel官网可以看到“i7-6950X”的官方报价为¥11053.74,上万元!
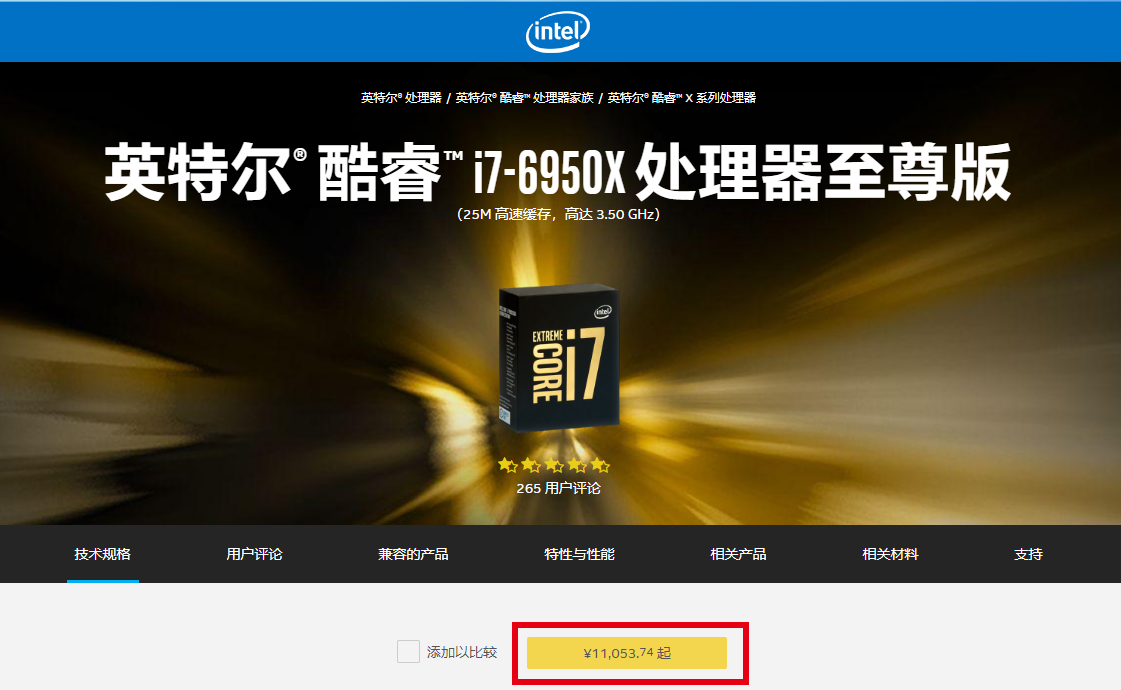
而在淘宝等渠道购买的正式版I7-6950X散片,只有3400元,价格差距如此之大。对于这种旧款CPU的散片(正式版)性价比还是蛮高的,所以推荐大家购买散片CPU(当然也会有很多朋友担心散片CPU的质量问题,这个确实不能保证每个渠道的U都是好的,看人品吧~)。下面对比一下“i7-6850K”、“I7-6950X”、“i75960X”以及“I7-6900K”这几款CPU。
| 基本要素 | 酷睿™ i7-6950X | 酷睿™ i7-6850K | 酷睿™ i7-5960X | 酷睿™ i7-6900K |
|---|---|---|---|---|
| 发行日期 | Q2’16 | Q2’16 | Q3’14 | Q2’16 |
| 光刻 | 14 nm | 14 nm | 22 nm | 14 nm |
| 内核 | 10 | 6 | 8 | 8 |
| 线程 | 20 | 12 | 16 | 16 |
| 基本频率 | 3.00 GHz | 3.60 GHz | 3.00 GHz | 3.20 GHz |
| 睿频频率 | 3.50 GHz | 3.80 GHz | 3.50 GHz | 3.70 GHz |
| 缓存 | 25 MB | 15 MB | 20 MB | 20 MB |
| TDP | 140 W | 140 W | 140 W | 140 W |
| 最大内存 | 128 GB | 128 GB | 64 GB | 128 GB |
| 内存类型 | DDR4 2400/2133 | DDR4 2400/2133 | DDR4 1600/1866/2133 | DDR4 2400/2133 |
| 内存通道 | 4 | 4 | 4 | 4 |
| PCIe通道 | 40 | 40 | 40 | 40 |
可以看到,四者均支持40条直通PCIe通道,当主板支持四路交火时,以“华硕RAMPAGE V EXTREME”为例,四张显卡分别占用(×8,×8,×8,×8)的速度,不会对性能产生太大影响。“I7-5960X”仅支持最高64GB的内存容量,这个对于我们的板子就略显不足了,相比“I7-6850K”和“I7-6900K”,在单核主频方面6850k基本频率为3.60GHz高于6900K的3.20GHz,不过核心数却没有胜出,二者基本属于同一等级的CPU,整体性能6900K略高于6850K,不过从性价比方面来看(散片),6850K的性价比还是略高的,散片售价仅2500元左右。“I7-6950X”是这几款U中性能最强劲的,虽然单核主频只有3.00GHz但是10核心20线程使其整体性能遥遥领先,可以从上文中的CPU天梯图中看到,尽管这个U是16年推出的,不过在当日的排行版也能排列到十几名,表现还是很出色的,唯一的不足就是价格略显昂贵,散片价格为3400元,之前一直想买2500元的6850K,后来一咬牙买了6950X。

总之,在选购CPU时,建议需要以下顺序:
- 筛选与主板插槽类型匹配的CPU。
- 查看CPU天梯图,了解CPU的整体性能排序。
- 在intel官网上将预选出的商品进行详细参数对比。
- 淘宝、京东对比散片价格,考虑入手性价比高的U。
个人建议:由于CPU这个东东如果正常使用基本没什么损耗,在选购散片时,会发现各个商家价格会有所差别,其实不一定要买最贵的,价格的不同可能是由于商家进货渠道引起的,只要认准“正式版”即可,避开“QS/ES”版本。
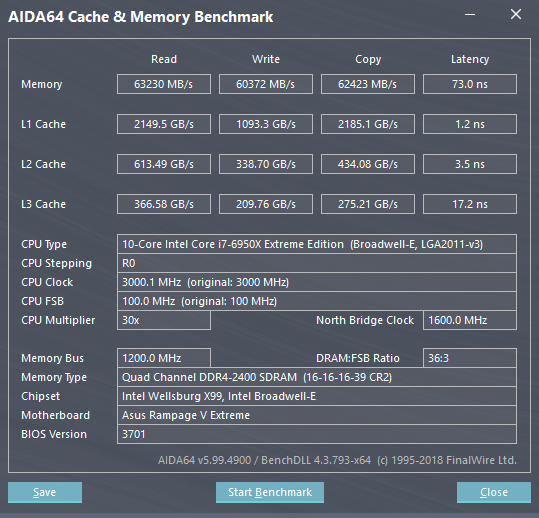
内存
内存是相对好选的组件,就没有必要多说了,以我个人来看,当然容量越大越好,毕竟现在内存价格低谷,抓紧买!
建议“海盗船复仇者”系列,我在选购内存的时候,基本把淘宝翻了个遍,看了很多厂家,价格都很贵,而且有很多都是小厂。对于海盗船复仇者系列内存,很多DIY玩家的首选,也不是没有原因的,现在一条16G的台式内存,只卖不到500元,很是便宜!而且口碑一直不错。

频率
目前市场上的内存大多在频率上做了很多营销手段,我们可以看到(2133 MHz、2400MHz、3000MHz、3200MHz以至于更高)的内存频率,同容量不同频率的内存条价格也相差很多,贵几百元的都有。但是我们是否有必要追求高频率的内存呢?
经过阅读网上一些大牛的文章,大多数人的观点都是,RAM频率对性能方面没有明显的提升,尤其是在做深度学习方面。其实频率只是各个厂商的一种营销手段,RAM公司会引诱大家购买“更快”的内存,其性价比并不高。有追求频率的钱,还不如多加一条内存。此处可参阅“Does RAM speed REALLY matter?”
所以我入手了“海盗船 复仇者”系列单条16GB最便宜的内存2400 MHz,一共上了4条,总共64GB。主板有8个内存插槽,先插四条构成四通道,剩余的留作扩展,不过此处一定注意, 在安装内存条的时候需要阅读主板说明书,基本每个主板都会给出推荐的插法,看好个插槽所在的通道,一定不要插错了。
SSD
在初期选购固态硬盘的朋友可能会经常看到SATA3固态硬盘与M.2固态硬盘,可能有朋友会有疑问:M.2是什么意思?和SATA3固态硬盘有什么区别?下面我们就简单科普M.2接口。

M.2接口
M.2是一种固态硬盘新接口,是Intel推出的一种替代MSATA新的接口规范,也就是我们以前经常提到的NGFF,英文全称为:Next Generation Form Factor。
M.2接口固态硬盘主要优势在于体积相比传统的SATA3.0、MSATA更小,并且读取速度更快,对于一些移动设备兼容性更好。
- M.2和SATA3固态硬盘的区别
目前固态硬盘(SSD)常用的接口主要有3种:
- SATA3 - 外形尺寸是2.5寸硬盘的标准尺寸,与2.5寸机械硬盘可以互换。
- mSATA - 接口尺寸与笔记本内置无线网卡相同,不过mSATA SSD的外形尺寸比无线网卡更大。
- M.2 - 初期称为NGFF接口,是近两年新出的接口,为专门为超小尺寸而设计的,使用PCI-E通道,体积更小,速度更快。
值得一提的是M.2接口固态硬盘又分为:SATA和PCI-E两种,虽说长得一模一样,但性能却是差之千里。此外,有些主板的M.2接口不一定对其支持,所以在买M.2固态硬盘的时候,还需要了解下接口兼容性,在购买主板和SSD时关注一下接口信息即可。
M.2有两种接口定义:Socket 2和Socket 3。Socket 2支持SATA或PCIe ×2通道的SSD,Socket 3专为高性能存储设计,支持PCIe ×4通道。在购买SSD时一定要确认是否走PCIe ×4通道,这样才性能最佳。
容量
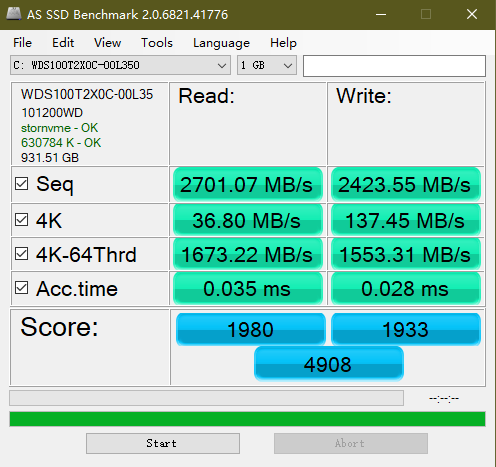
在容量方面,大多数用户512G就够用了,毕竟SSD不是作为数据存储盘使用,而是作为系统盘安装程序使用,但由于目前SSD价格下滑,决定还是入手一个1T的,这样更充足。
经过仔细挑选,最终筛选出两款SSD,“Samsung/三星 MZ-V7S1T0BW 970 EVO Plus 1TB”和“WD/西部数据 WDS100T2X0C 1TB”,比较推荐三星这款,三星的固态一直是业界最好的,速度最快的,不过西数的SSD也在第一梯队,二者价格相差300元左右,“三星970 EVO Plus”速度略高于“西数WDS100T2X0C”,官方宣传三星这款读取速度3500Mb/s、写入速度3300Mb/s,西数这款读取速度3400Mb/s、写入速度2800Mb/s,如果经费允许的朋友推荐三星这款,不过我选择了较为便宜的西数SSD。其他品牌的没用过,不能妄加评论,但是三星和西数的固态硬盘一定是第一梯队了。
机械硬盘
机械硬盘容量视个人情况而定,对于计算机视觉工程师,如果需要存放大体积数据集,就买大一点的,毕竟HDD不贵(但一定记住避开希捷、避开希捷、避开希捷!之前笔记本加装过希捷硬盘,太渣了)。我最后入手了“西部数据 WD40EZRZ 4TB 蓝盘”,买的OEM版本,比官方价格低100多,用着还不错。
显卡
显卡的选择,Tim Dettmers的《Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning》一文已经分析的非常透彻,我也是参考了他的文章购置了RTX 2070显卡,各位朋友可以深入阅读该文章,此处只做简要阐述。
性能对比
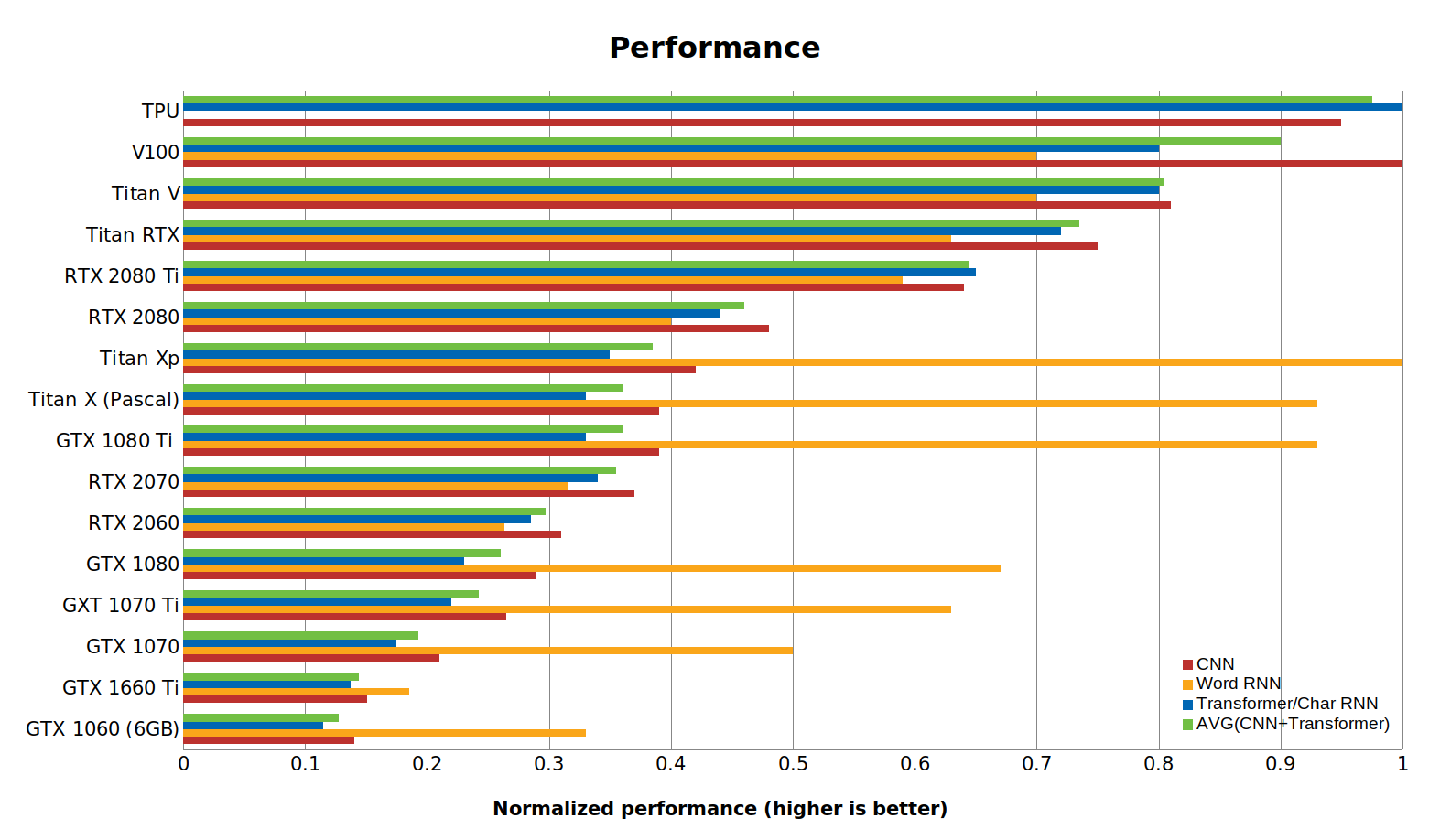
GPU和TPU的标准化性能数据。越高越好。RTX卡使用16位计算。使用PyTorch 1.0.1和CUDA 10完成基准测试。
性价比分析
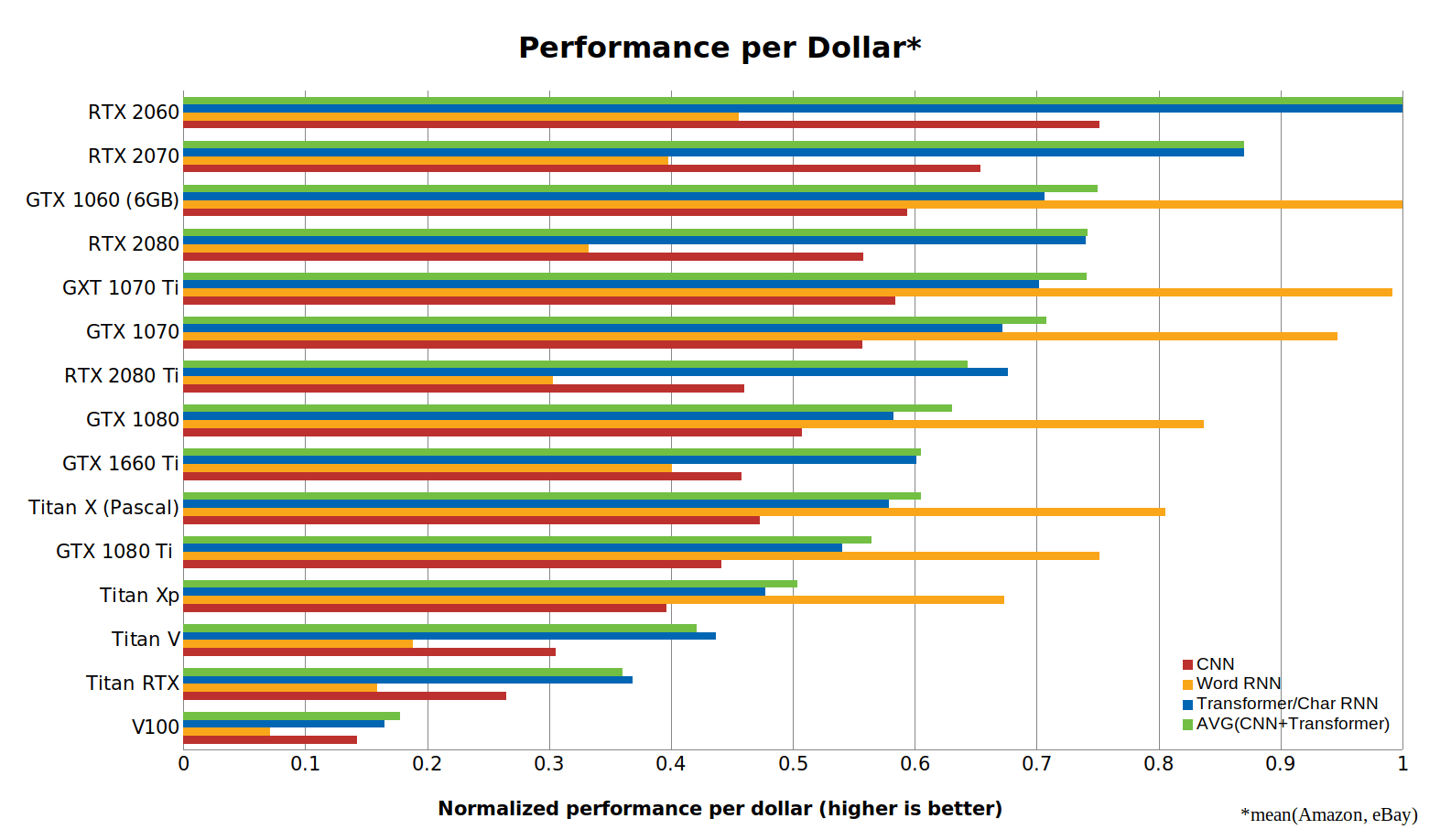
卷积网络(CNN),循环网络(RNN)和Transformer的性能/价格。越高越好。RTX 2060的成本效率是Tesla V100的5倍以上。使用PyTorch 1.0.1和CUDA 10完成基准测试。
注:以上图转载自《Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning》
经过Tim的分析,更倾向于购买RTX 20系列显卡,因为其独有的“Tensor core”可以支持加速FP16的运算,减少显存的支出,也能减少计算复杂度,
整体建议(转载)
最佳GPU:RTX 2070
避开GPU:任何Tesla; 任何Quadro卡; Titan RTX,Titan V,Titan XP
实惠但价格昂贵:RTX 2070经济
实惠且价格便宜:RTX 2060,GTX 1060(6GB)。
我有点钱:GTX 1060(6GB)
我几乎没有钱:GTX 1050 Ti(4GB)。或者:CPU(原型设计)+ AWS / TPU(训练); 或者Colab。
我做Kaggle:RTX 2070
计算机视觉或机器翻译研究员:GTX 2080 Ti,如果您训练非常大的网络获得RTX Titans。
NLP研究员:RTX 2080 Ti使用16位。
我开始深入学习并且我认真对待它:从RTX 2070开始。在6-9个月之后购买更多RTX 2070并且您仍然希望投入更多时间进行深度学习。根据您接下来选择的区域(启动,Kaggle,研究,应用深度学习),销售GPU并在大约两年后购买更合适的东西。
我想尝试深度学习,但我并不认真:GTX 1050 Ti(4或2GB)。这通常适合您的标准桌面,不需要新的PSU。如果它适合,不要购买新电脑!
选购
看了Tim给出的建议,我最终选择了RTX 2070显卡,虽然只有8G显存,不过使用16位运算,主流网络也都能跑起来。对于品牌的选购我只建议不要买灯效、不要买超频,你要相信一点,同一个型号的显卡(例如RTX 2070),任何厂家任何款式的商品在性能上均没有什么性能差距,价格差距主要体现在所谓的超频、灯光效果上,我个人的建议是完全没有必要把钱花费在这上面,关注一下散热,一线厂商的用料都不会太差。
我选购了“影驰 RTX2070 大将”,3400元。对于经费充裕的朋友,RTX 2080 Ti也是一个非常好的选择,我之后扩展可能会入手2080 Ti

电源
通常,我们需要一个足以容纳所有未来GPU的电源。电源的稳定性也对组件的寿命有很大影响,因此购买一个优质的电源是很有意义的。
因为一个主机最终要的功耗组件是GPU和CPU,我们可以通过将CPU和GPU的功耗累加,并且附加其他组件大约额外10%W来计算所需的功率。网上也有很多计算功率的网站,但大多组件不是很全面,没有什么参考价值, 我的建议就是尽量上大功率电源,留作之后升级显卡使用。还要注意,模组电源支持的PCIE口数量,例如上面我所购买的RTX2070影驰大将,电源接口为8+6pin的,占用默许电源两个8pin的PCIe供电口,如果电源给的供电口只有6个8pin供电口,那么我们只能给3张显卡供电。这个问题需要注意一下。

对于电源,我有两款产品推荐:“鑫谷GP1350G 额定1250W 全模组”和“长城巨龙服务器电源 1250W 全模组”,二者价格差不多,我买的鑫谷这款。
散热器
CPU散热部分,之前一直想上一个风冷节省支出,但是由于I7-6950X已经140W了,风冷根本压不住,所以上了240双冷排的水冷,在选购散热器时注意与商家咨询该散热器是否能压住该功率CPU。我入手的“爱国者(aigo)冰塔T240 极光版”,散热效果很好。
机箱
机箱看个人喜好吧,尽量大一点,散热能好些。我入手的“爱国者(aigo)月光宝盒 破晓”。
风扇
风扇这个东西还挺贵的,普通的大约20多一个,真是不明白贵在哪里,购买风扇踩了个坑,以为各种风扇都一样,买便宜的就好,入手了京东最便宜的风扇10元一个,看标注风力之类的都比爱国者极光好,但是实测风力没有爱国者极光风扇强大,不过极光风扇噪音有点大。

组装
装机部分随便上张图意思一下吧~总之是忙了一整天才弄好。



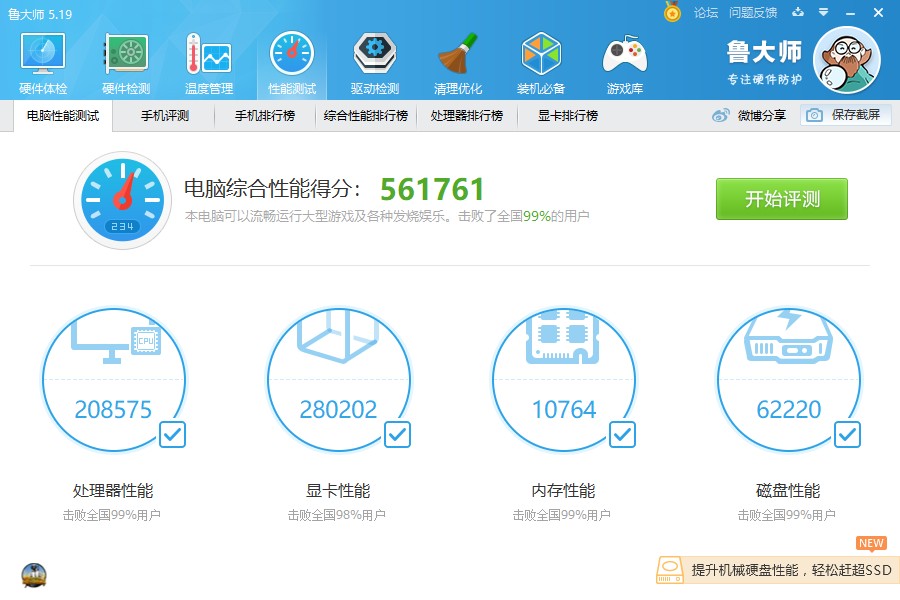
性能测试